[ Overview || TCP | C++ | Python | REST | WebSocket || Models | Customization | Deployment | Licensing ]
By default, requests to the Engine use a pre-built vocabulary and grammar with a very large number of words and generic English grammar. You can specify the grammar and vocabulary the Engine recognizes by passing a grammar in the JSON request that precedes the audio. You must also pass a properly formatted lexicon. Every word that appears in the grammar must appear in the lexicon.
{
"words": [
{"word": "adam"},
{"word": "arlo", "phones": "AA R L OW"},
{"word": "marilou", "soundslike": "mary lou"},
{"word": "[silence]", "phones": "SIL"},
{"word": "[unknown]", "phones": "OOV"}
],
"grammar": {"type": "looped-words"}
}The lexicon consists of an array of lexical entries in the words
field. Each lexical entry has the spelling in the word field
("adam", "arlo", and "marilou" in the above) and optional
additional fields that describe the pronunciation (e.g. "phones": "AA R L OW" and "soundslike": "mary lou" in the above). The word
is what gets printed in the transcript by the engine, and can be
anything. For more information on the optional fields that describe
the pronunciation, see Custom Pronunciations.
| Field | Type | Default | Description |
|---|---|---|---|
words |
array of JSON objects | N/A | List of words that the grammar recognizes. |
grammar |
JSON object | N/A | A custom grammar JSON object, as specified below. |
Each object in the words list corresponds to a word in the grammar's lexicon. The objects
have the following fields.
| Option | Type | Default | Description |
|---|---|---|---|
word |
string | N/A | The spelling of the word. |
soundslike |
string | N/A | English-like "sounds out" pronunciation. |
phones |
string | N/A | A space delimited phonetic sequence representing the pronunciation of the word. |
See Custom Pronunciations for more information on the "soundslike"
and "phones" options.
The lexicon can also handle the cases where a speaker doesn't speak at all, or says words
that aren't included in the lexicon. These cases can be resolved by including entries in
the lexicon with pronunciation "SIL" for silence or "OOV" for out-of-vocabulary.
For example, the use of a silence word pronounced as "SIL" can be useful when the grammar requires
a forced choice among the words in the lexicon, as a "None of the above" option.
The word field for these entries can be assigned to be anything.
A given word can also have multiple pronunciations.
{
"words": [
{"word": "0", "phones": "Z IY R OW" },
{"word": "0", "phones": "OW" },
{"word": "1", "phones": "W AH N" }
],
"grammar": {"type": "looped-words"}
}Short phrases can also be specified by abutting the pronunciations. For example:
{"word": "Adam Janin", "phones": "AE D AH M JH AE N IH N"}The grammar field must be a specific grammar JSON object.
All grammars must have a field "type" specifying either
"looped-words", which will make the grammar a simple word loop
over the words given in the lexicon,
"single-word", which recognizes a single word from amongst
equally likely options given in the lexicon, or "graph", which
allows much more complex grammars.
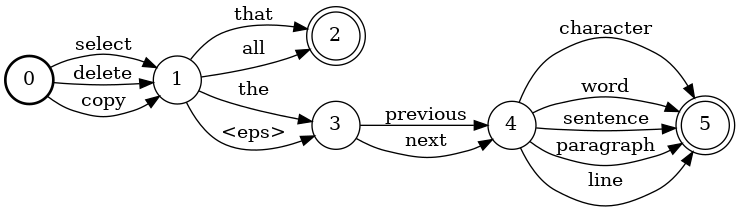
The grammar is specified as a series of states and arcs. Think of a state as a moment in time between words. The set of words the engine can recognize at that time is restricted to the words on the arcs coming out of that state. As a concrete example:
 .
.
In the example, from state "3", the only words that are allowed are
"previous" and "next". You can figure out all legal phrases by
starting at state "0", picking an arc, and following it to the next
state.
-
"select the previous line"goes in order state"0", "1", "3", "4", "5"; -
"delete all"goes in order state"0", "1", "2". -
"paste that"cannot be recognized because there is no arc leading out of the start state (state"0") with the word"paste".
The special word "<eps>" indicates that the arc can be traversed
without recognizing any word. In the
example above, this allows recognition of "select previous word" by
moving from state "1" to state "3" through the "<eps>" arc.
There can be only one start state. Recognition can stop only at exit
states, indicated in the diagram with the double circles. So "copy the previous" will not be recognized because state "4" isn't an exit
state. There can be any number of exit states.
The JSON used to specify a grammar encodes diagrams like the one above. See the file short-text-grammar.json for the full JSON including the lexicon. Below are excerpts that demonstrate the format.
{
"words": [
{
"word": "all",
"phones": "AO L"
},
...
],
"grammar": {
"type": "graph",
"start": "0",
"arcs": [
{
"from": "0",
"to": "1",
"word": "select"
},
{
"from": "0",
"to": "1",
"word": "delete"
},
...
{
"from": "4",
"to": "5",
"word": "line"
}
],
"exits": [
"2",
"5"
]
}
}The JSON object for the grammar must have the following fields.
| Field | Type | Default | Description |
|---|---|---|---|
type |
string | N/A | The type of grammar, "graph", "single-word", or "looped-words". |
start |
string | N/A | The start state of the grammar. |
arcs |
array of JSON objects | N/A | List of transition arcs. |
exits |
array of strings | N/A | List of states where a sequence of arcs through the grammar can end. |
The lexicon is required to contain all words (other than "<eps>") that
occur in the grammar. The grammar must have one (and only one) start state. The label
for the states can be any string, but integers starting from zero are
typical. The grammar must include a list of the arcs. The arcs each have
a start state, an end state, and the word. They can also optionally
have a weight(cost) . Finally, the grammar must specify which
states are exit states.
Each arc is a JSON object with the following format.
| Field | Type | Default | Required | Description |
|---|---|---|---|---|
from |
string | N/A | Yes | Source state of this arc. |
to |
string | N/A | Yes | Destination state of this arc. |
word |
string | N/A | Yes | Word of this arc. |
weight |
non-negative number | 0 | No | "cost" associated with this arc. See below. |
Each arc can also have a weight. Weights are a way to assign costs/scores to the different arcs that the Engine could take. When processing a segment of audio, the Engine computes a weighted sum of the acoustic score (from the acoustic model), and the graph score (the sum of the arc weights), and outputs the path through the graph with the lowest cost. By setting the arc weights, we can prioritize different paths through the grammar. In each of the examples in this document, the arcs take the default weight of 0.
As of v1.9.7 of the Engine, the reply will include a reached_exit field to indicate whether an
exit state of the custom grammar's graph was reached at the final time step.
This can be helpful in scenarios such as forced alignment where an incomplete path might otherwise
be recognized, especially if there is a severe mismatch between the audio and the transcript-derived
graph -- or if the Engine's decoder is run with very constrained pruning (e.g. speed set to 9).
Here is an example of running the grammar above with an audio file of "copy previous word":
curl -sLO mod9.io/copy_previous_word.wav
(jq -sc '.[0]*.[1]' short-text-grammar.json \
<(echo '{"endpoint": false}');
cat copy_previous_word.wav) | nc $HOST $PORTWe can also try:
curl -sLO mod9.io/select_that.wav
(jq -sc '.[0]*.[1]' short-text-grammar.json \
<(echo '{"endpoint": false}');
cat select_that.wav) | nc $HOST $PORTIMPORTANT: even though the grammar and/or lexicon will be often be
rather large, they are passed as standard request
options to the ASR Engine. These must be
represented within a single JSON object, encoded as a string that has
no newline characters. If you have jq installed, you can use e.g.
jq -c . short-text-grammar.json to reformat with no extra whitespace.
North American phone numbers are highly structured. Specifically, they're 7 digit numbers with optional
3-digit area code, and an optional prefix "1".
By representing this structure directly in a custom grammar, we can achieve much higher accuracy
in transcribing audio with spoken phone numbers.
The image below graphically represents a custom grammar for phone numbers with area codes (and an optional "1" in front).
To read off a phone number, start at the left in state "0", and follow an
arc out to a new state. Repeat this until reaching the end state "11". Note that "<eps>" represents
an empty "epsilon" arc, where nothing is said between the connected states. For example, the "<eps>"
arc from "0" to "1" encodes the fact that the "1" country code prefix is optional.
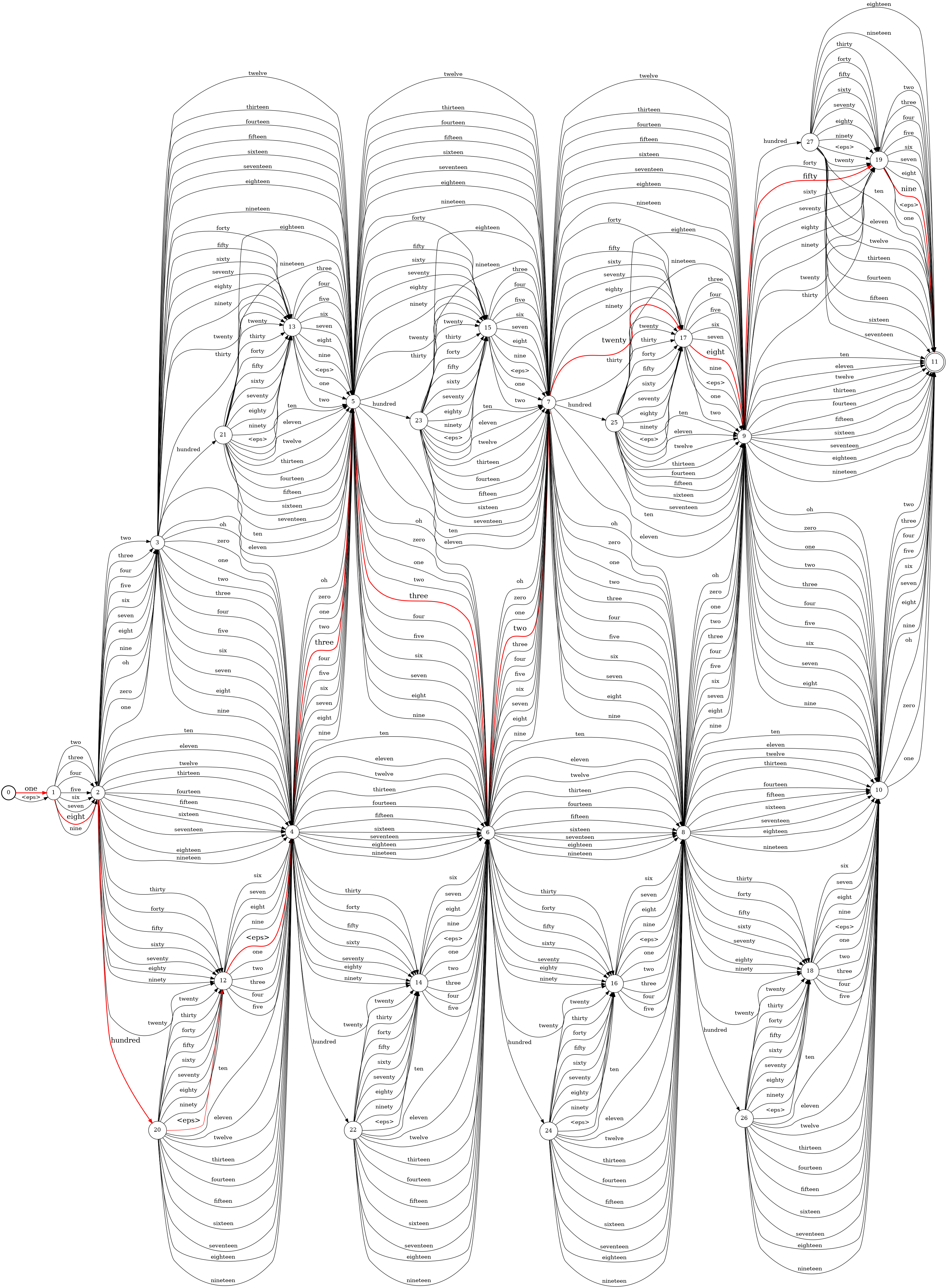
Click for full-sized image.
The path highlighted in red is one way of saying the phone number 1-800-332-2859. There are
many other ways of reading off the same phone number. For example, the number could also be read as
"one eight zero zero thirty three two two eight five nine". This would be a different path from state "0" to state "11".
The full phone number grammar JSON can be downloaded here.
©2019-2025 Mod9 Technologies (Version 1.9.9)